一、引言
对于我司的长连接架构而言,我们除了全面 MQTT 化之外,也可以选择逐渐走向全自研方向。从我司现有的业务场景与技术需求来看,使用自定义二进制协议也可以实现。
基于我司需求的长连接整套架构的重新优化,我们需要实现高可控,高性能,高产出的技术形态,并与业务深度结合的形式,提供一个清晰明确的迭代路径。
二、现状与问题
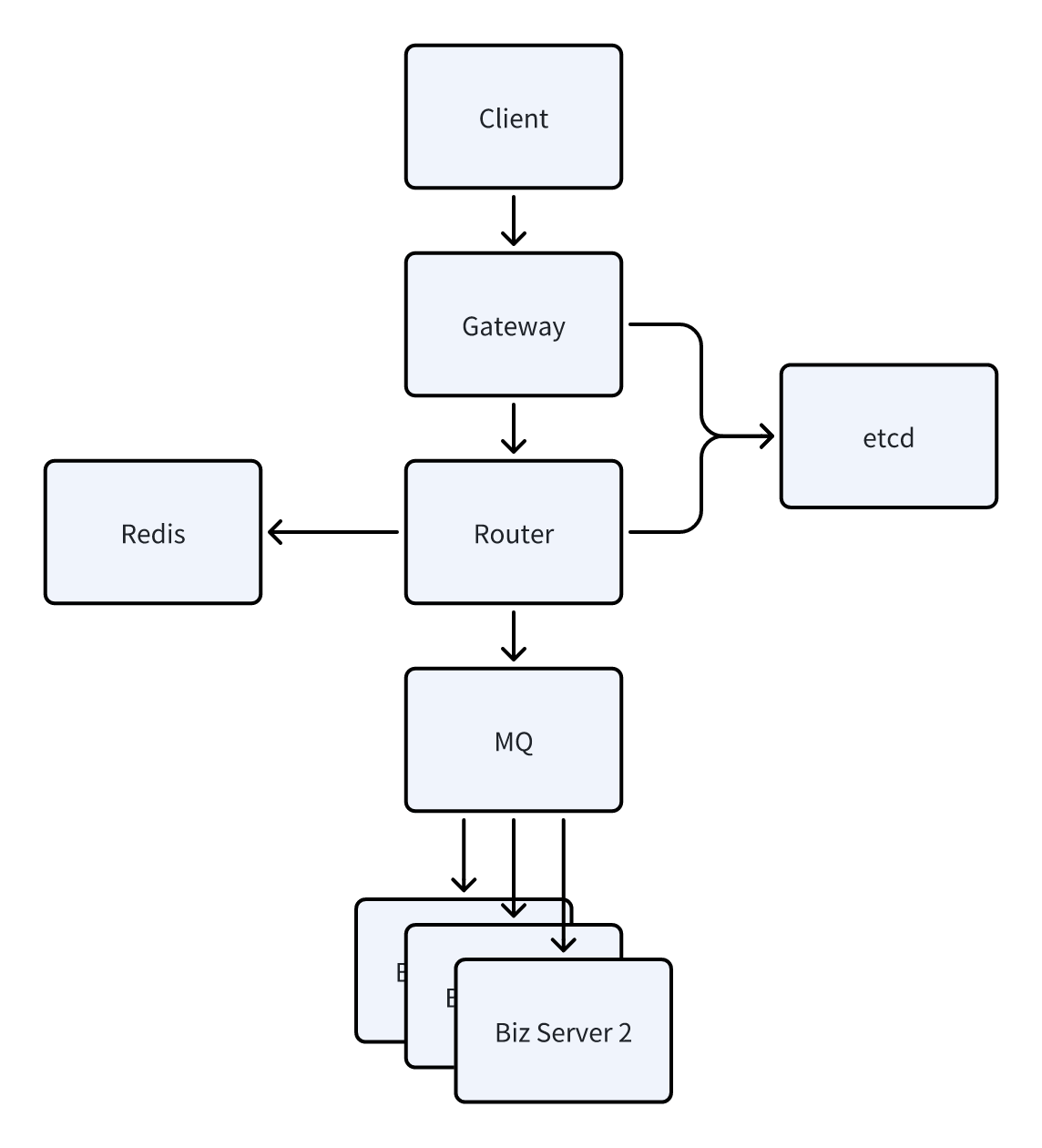
目前长连接消息架构有几个问题需要考虑:
- 对于基于C/S架构的长连接服务,在我司这种多场景多模态共享连接的消息机制下,发布订阅机制其实是没有必要的,取消订阅环节可以减少业务复杂性,在非对等连接状态下,客户端没必要维护一个本地服务消息通路路由,这种模式一般是用于p2p下直接向其他用户发送消息的模式才使用的,在我司的业务场景下,由服务端维护用户状态即可
- 网关层感知具体协议内容成本太高,在网关层做json拆包过于靠近业务,难以保持架构不被业务污染
- 由于网关层不方便感知我司协议具体内容,难以做统一的T票验证、QoS、遗嘱消息、离线消息等逻辑的统一控制处理
- 由于采用MQTT的消息机制,无法统一控制整体消息的全局唯一性,导致消息的推拉机制与读写扩散机制很难准确控制,经常在这类问题上遇到逻辑冲突或者逻辑bug
- 消息从网关往业务的投递机制固定,难以满足高性能短时延场景满足需求
- 由于连接状态管理也混淆了MQTT应用层协议与TCP这种连接层协议,难以判断用户连接状态是在哪一层出现的问题,同时如果未来要支持多端同步也会成为技术卡点
根据以上几点,我们可以从三个方面对整体长连接层面的技术点进行优化:
- 优化传输协议,提高网关层处理效率,并简化业务对消息业务的处理流程
- 优化控制逻辑,将基础控制能力通用化,使基础设施下沉
- 改进消息处理模型与投递机制,提高消息处理效率
三、优化协议
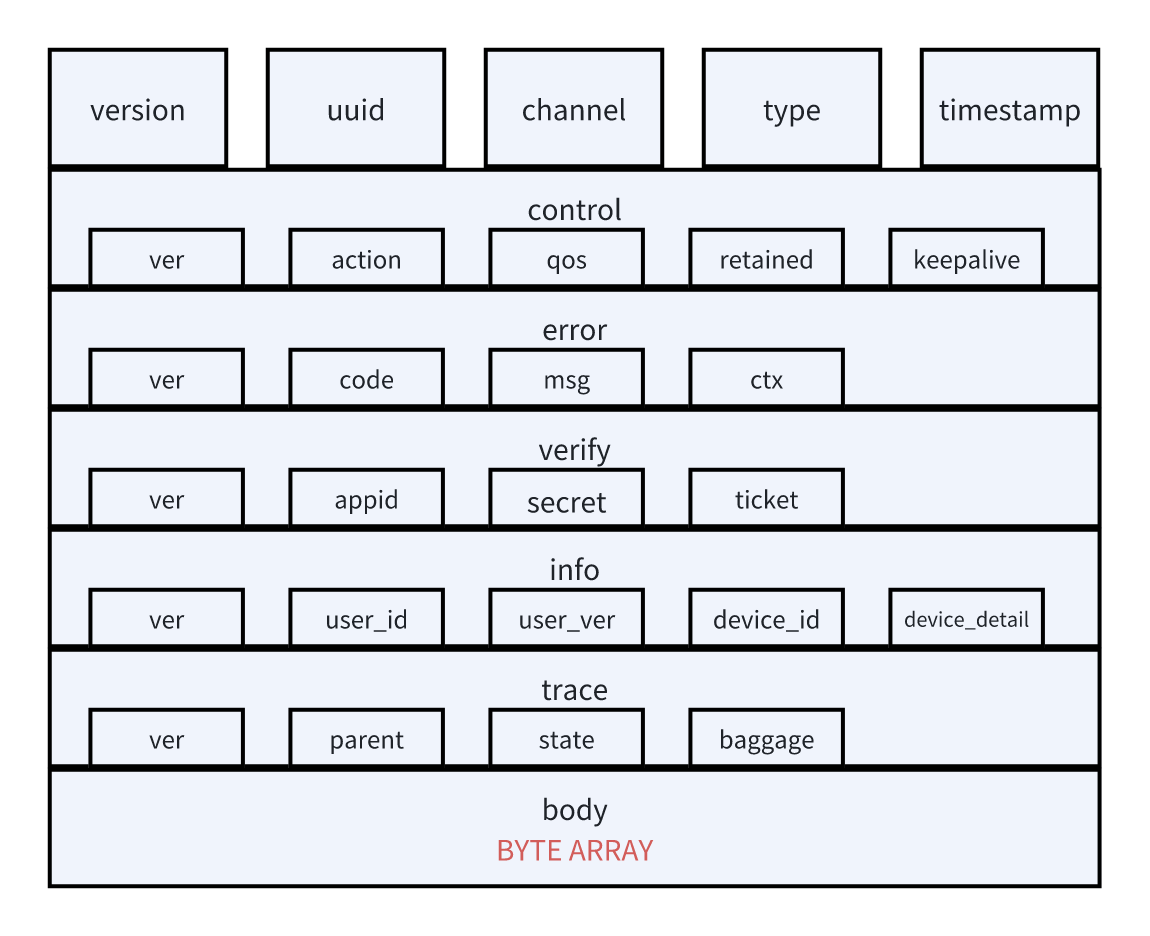
协议上我们剥离 MQTT 的所有包装,重构 MQ 协议结构,将原本的多重 json 嵌套模式修改为控制报文+消息体的分段式结构,通过对协议控制字段的快速序列化完成公共能力的基础设施化,其大致形态如下:
控制报文
对于控制字段,我们可以参考 MQTT 的形式,将其封装为一个固定的 Protobuffer对象,其 Protobuffer 伪代码大致如下:
syntax = "proto3";
package MQ;
enum MQActionType {
CONNECT = 0;
CONNACK = 1;
DISCONNECT = 2;
PINGREQ = 3;
PINGRESP = 4;
MESSAGE = 5;
MSGACK = 6;
}
// qos类型
enum MQQoSType {
None = 0;
AT-LEAST-ONCE = 1;
};
// Error实体
message MQError {
// 协议版本
int32 ver = 1;
// 错误码,负值为网关异常,正值为业务异常
int32 code = 2;
// 错误信息或关键信息
string msg = 3;
// 上下文信息,可以携带一些额外信息(key: 内部调试信息采用 _xx_ 命名,与额外信息区分)
map<string, string> ctx = 4;
}
message MQControl {
// 协议版本
int32 ver = 1;
// 控制动作
MQActionType action = 2;
// qos等级
MQQoSType qos = 3;
// 是否启用保留消息
bool retained = 4;
// Keep Alive
int32 keepalive = 5;
}
message MQVerify {
// 协议版本
int32 ver = 1;
// 应用 id
int32 appid = 2;
// 应用密钥
string secret = 3;
// t 票
string ticket = 4;
}
message MQUserInfo {
// 协议版本
int32 ver = 1;
// 用户 id
int32 user_id = 2;
// 用户版本
int32 user_ver = 3;
// 用户设备 id
string device_id = 4;
// 用户设备信息
string device_detail = 5;
}
message MQTracingInfo {
int32 ver = 1;
// traceparent,形如00-xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx-yyyyyyyyyyyyyyy-zz
string parent = 2;
// tracestate,形如key1=value1,key2=value2,key3=value3
string state = 3;
// baggage,形如key1=value1,key2=value2,key3=value3
string baggage = 4;
}
// 消息实体
message MQMessage {
// MQ 协议版本
oneof version_oneof { int32 version = 1; };
// 全局唯一 id
oneof uuid_oneof { int32 uuid = 2; };
// MQ 通道id,即会话id
oneof channel_oneof { string channel = 3; };
// 业务类型
oneof type_oneof { string type = 4; };
// 时间戳
oneof timestamp_oneof { int64 timestamp = 5; };
// 控制协议
MQControl control = 6;
// 异常协议
MQError error = 7;
// 验证协议
MQVerify verify = 8;
// 用户信息
MQUserInfo info = 9;
// 追踪协议
MQTracingInfo trace = 10;
// 消息体
oneof body_oneof {
bytes byte = 11;
};
}
使用pb协议作为二进制流直接进行数据传输,放弃MQTT报文封装,并将多种类型字段分开处理,如在网关的接入层只需要判断协议版本和channel类型即可做路由转发,对于需要进行接入层处理的控制协议的识别通过直接的控制对象即可进行识别操作,而无需进行数据的多次解包。
选择pb作为协议载体主要考虑到可以大幅度简化二进制协议的构造协议的开发工作,如果网关层的基础流控对于pb协议的解析开销很大,则可以使用双段表述设计,将基础的5个字段进行二进制固定化,然后提供一个可变长度容器,通过在固定报头中提供可变长度信息的方式,将对象化数据以pb字节流的形式进行直接封装。
四、统一协议控制与通用网关
由于我们拆掉了MQTT的协议包装,因此网关层现在可以直接感知control段与verify段对于消息控制的整体描述。
control字段
control段包含了action、qos、retained、keepalive四个控制字段,通过这四个字段可以判断本次会话或者本条消息的客户端行为状态。
action
action表述了消息类型,对于我司的业务场景,我们仅需实现7种消息行为即可:
- CONNECT 表示连接请求,说明是客户端向服务端请求建立连接
- CONNACK 表示服务端收到了来自客户端的连接请求,返回给客户端说明可以发送后续消息
- DISCONNECT 表示主动断开连接,如果客户端向服务端发起是客户端主动断开,如果是服务端向客户端发起则是提下线
- PINGREQ 表示客户端发送心跳协议,在keepalive字段为1时可用
- PINGRESP 表示服务端收到了客户端的心跳消息,返回给客户端,在keepalive字段为1时可用
- MESSAGE 表示这是一条普通消息类型,具体内容得参考body字段内容
- MSGACK 表示接收方收到了来自发送方的消息,用于实现QoS 1下的消息到达保证
qos
qos字段是针对具体消息进行控制,仅对action为MESSAGE时生效,当qos为0时不进行处理,当值为1时则需要消息接受方返回MSGACK的action。
retrained
该字段用于控制该消息是否由服务端进行离线存储,为0时不进行处理,为1时进行离线消息存储,在接受方下次上线时如果未读则进行投递。
keepalive
该字段用于控制客户端连接保活,防止出现半连接状态,该值每次赋值都会修改当前会话的连接保活设置,当该值为0时客户端不发送心跳包,当该值大于1时客户端发送PINGREQ给服务端,服务端返回PINGRESP用于确认状态,数值代表心跳间隔时间,时间单位是秒。
verify字段
verify字段包含了appid、secret、ticket三个字段,通过这三个字段可以对客户端的消息进行验证。
appid
用于判断客户端发起连接时所属的应用场景,例如app本身为10000等。
secret
针对appid进行的密钥验证,用于判断消息应用场景是否合法。
ticket
针对需要进行t票验证的场景,可以判断是否是合法的客户端。
小结
通过扁平化控制字段可以实现在网关层进行部分通用逻辑控制,并且便于与开放平台等进行应用场景的鉴权融合。
五、改进消息处理模型与投递机制
我们的消息推拉逻辑处理之所以难以控制,主要是因为我们的消息缺乏全局统一或者会话统一的可靠递增标识。
以我司现有的消息服务无法保证用户在上下行中如果丢失消息,可以随时找回来,并且由于对于消息排序是通过客户端本地的时间戳排序,这个顺序与服务端无法保证绝对一致,只能通过ack时服务端进行uuid重赋值,但是uuid本身也没有递增性质,导致中间到底是否由缺失无法识别。
而且递增的消息id有以下几个好处:
- 使用数字可以节约存储空间,并且可以利用存储引擎的特性让相邻消息存储在一起,降低消息写入与读取的性能损耗
- 使用自增数字可以减少数据读取的随机IO,并且可以方便的保证id的唯一性
- 使用自增数字可以看作是时序数据,可以方便做消息的分页拉取,提高分页性能
因此想要整套逻辑通用化处理,需要重新设计唯一id机制,并基于唯一id来设计消息推拉机制与投递机制。
消息id设计
如何设计自增唯一id?一般对于IM系统,主要由全局递增id、用户递增id、会话递增id三个级别。
全局递增id:一般来说全局递增id的维护成本太高,目前可知Twitter的Snowflake是一种全局递增id的机制,但是也只是worker级别的,且Twitter属于timeline类型feed应用,不能算作IM系统,消息并发量级不可比。典型代表:Twitter。
用户递增id:指消息 ID 只保证在单个用户中是递增的,不同用户之间不影响并且可能重复。典型代表:微信。如果是写扩散系统的话信箱时间线 ID 跟消息 ID 需要分开设计,信箱时间线 ID 用户级别递增,消息 ID 全局递增。如果是读扩散系统的话使用用户级别递增必要性不是很大。典型代表:微信。
会话递增id:指消息 ID 只保证在单个会话中是递增的,不同会话之间不影响并且可能重复。典型代表:QQ。
对于我司的应用场景来说,其业务形态更接近QQ的模式,采用会话级别的id自增机制成本会可靠的多,同时需要服务端维护会话 id 自身的全局递增性质,即采用全局会话ID+会话内自增id的机制来进行控制。至于具体的会话id的设计则可以沿用现有的sessionid的生成机制来完成,目前sessionid可以基本保证全局唯一性。
而会话内的消息递增机制,则需要根据具体的应用场景来进行区分,例如在写扩散模式下我们只要保证在同一个会话中消息id可以保证单调递增即可,但是在读扩散模式下最好需要保证消息id是连续递增的。
读写扩散和推拉机制
对于如何控制读写扩散模型,可以采取基于会话id识别与读写比计算的机制来进行读写扩散控制:
- 对于单聊、普通群聊场景采用写扩散模型,为每一个用户创建一个Inbox,所有消息都投递到这个Inbox中,用户每次上线后直接向用户投送所有离线消息,当消息在服务端的用户离线队列中被消费,就清空该段消息,由于会话内消息id自增,因此批量进行连续消息处理性能会很高。当用户拉取历史消息时通过消息id即可拉取,即使出现重复消息也可以快速去重。这种模式下由于每个用户都有自己的Inbox,因此获取信息的效率很高,但是对于群聊会放大写操作,放大倍数等于群聊用户人数,单聊场景下单会话的读写比例大概在1:2到2:2之间,群聊场景下则一般在(N-n):N左右,其中N为总用户数、n为长期不上线用户。因此原则上我们可以根据读写数据的费用比进行调整,通过计算每个群聊session中离线时间超过一周(或其他时间长度)进行降级控制。
- 对于大型群聊、临时群聊等,可以采用读扩散模型,每一个群聊会话建立一个单独的Inbox,并保证该Inbox内的所有消息全部连续递增,用户进入该会话后向服务端发送最后一个会话id拉取一定量的历史消息,并由客户端主动定期向服务端拉取消息(如1s拉取一次)。当用户处于会话外时,服务端只定时推送向所有用户推送该会话更新了消息的状态,通过这种方式节约通信成本。
- 对于命令消息等消费型场景,可以采用纯推模式,客户端不会主动向服务端拉取消息,但客户端可以记录每个命令的消息id,服务端可以为每个用户独立设置一个命令消息的Inbox用于一次性消费。
通过基于会话id+离线用户数计算进行模式区分,以实现读写扩散机制的平滑处理。由于这个方案是基于具体的场景的读写比例与用户状态进行动态调整的,因此在制定读写推拉模式的切换策略前需要先能收集到对应数据。大概公式如下:(单次读取费用*(会话用户总数-离线用户数)+单次写入费用*会话用户总数)/(单次读取费用*会话用户总数+单次写入费用),当这个结果大于1说明从费用角度适合转入读扩散模式,反之适合写扩散模式。
消息投递机制
原来基于MQTT的场景下我们的消息基本都是通过两条topic进行传递,在新业务场景下,客户端只要与网关建立了连接状态,就可以接受到所有消息,因此原本基于MQTT订阅机制的消息投递路径也需要进行调整。
新模式下应当由业务方向网关进行用户状态的注册,再由网关进行对用户的channel进行控制,由于不在需要同步客户端与服务端的订阅状态是否同步,也避免了出现由于状态不一致导致的异常问题。业务方本身也不需要保持用户状态的管理,直接向网关接口进行请求即可,这样也减轻了业务方的状态维护压力,业务方只需要持有用户场景属性表即可。
六、如何实施
由于目前我司本身的架构就是相对传统的C/S架构,因此只要将相应的协议处理能力放到网关层处理即可,对于长连接架构形态本身不需要做太多调整,更多的是对协议逻辑的调整与原本业务端的能力实现进行通用化下沉。
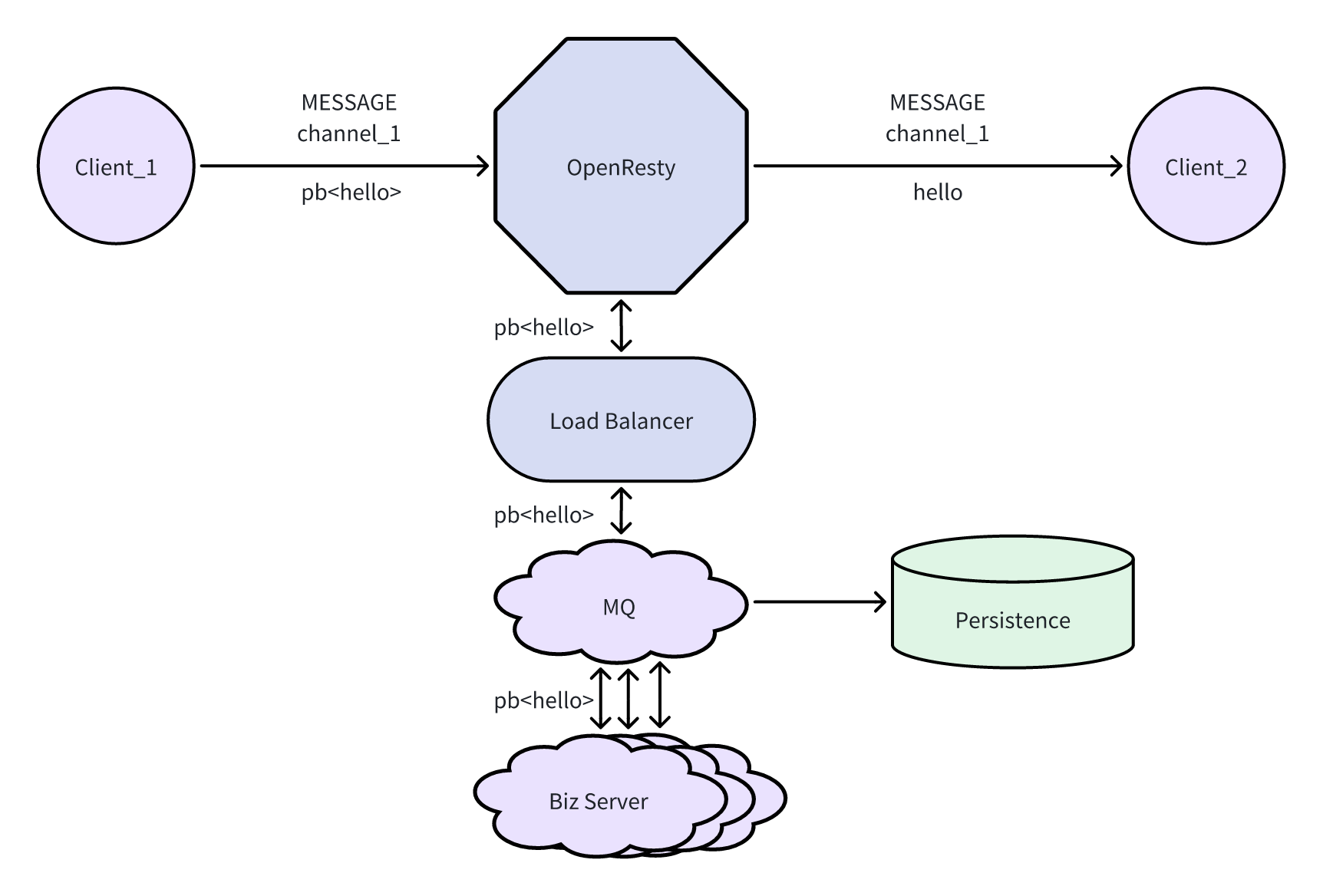
对于具体的实施计划可以分为以下几个阶段逐步完成:
- 完成自增id服务的建设
- 创建一个新网关,新网关层开发推拉机制与持久化层的集成,逐步将存储迁移到网关层直连
- 客户端升级协议迁移到新网关,并完成协议适配
- 优化控制字段的处理逻辑,完成全部的客户端接入端切换