背景
技术背景
在22年,我们的主要是以平台化为主的技术发展方向,其中在去年的规划文档中,我们大概提出了容器化的概念与一个初步的演进方向(如下图所示)。
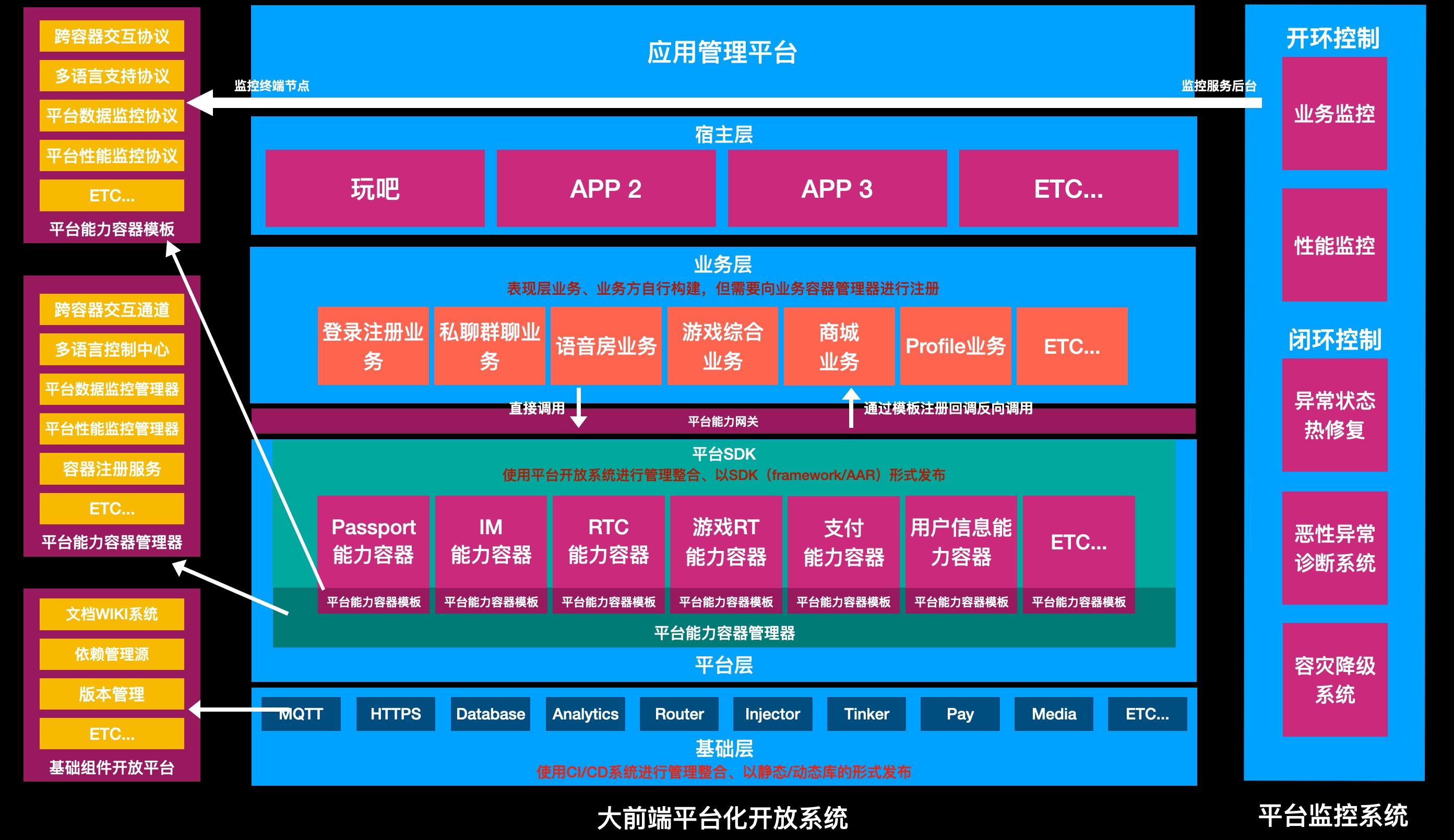
经过一年的尝试与不断的调整,我们逐渐总结出了之前架构设计的一些问题,明确了一些模糊的概念,建立了一些基础设施,通过这些积累,我们清晰的认识到适合于整个我司平台的客户端应用架构应该是什么样的。
去年一年我们的Rust基建逐步成熟,具有Rust开发能力的人员对这个技术方向不断深入;组内同学对跨平台交互逐渐熟悉,并有了一定的跨平台UI建设的积累;部分领域架构也有了统一的设计,对特定领域的技术演进也有了一定的沉淀;游戏在客户端中的重要性逐渐提升,App本身逐渐往平台支撑的方向演化。这一切都提示我们,之前的容器化架构在设计上存在着诸多问题。所幸去年的精力在容器化方向前进的并不深入,并且平台化相关工作作为前置条件,完成的进度也尚可。
接下来我们从业务背景的角度去讨论未来客户端的技术规划方向。
业务背景
23年公司的主要业务方向是围绕游戏业务建设,不管是自研游戏和三方游戏接入我司,还是自研游戏以单包的形式发布,客户端都需要做以下几个方面的探索:
一、与游戏引擎深度结合
- 我司业务能力与引擎深度融合,抹平不同游戏引擎之间的差异,实现我司对外的能力完全一致
- 打通跨业务场景调用能力,建立游戏业务,原生业务,Web业务之间的通信机制
- 建设对游戏业务的监听追踪能力,提高线上游戏业务的稳定性
二、根据需求提供多种集成方式
- 以SDK形式提供平台能力
- 可以在我司平台快速接入第三方游戏,同时彻底隔离平台可能对三方产品的耦合
行业风向
这两年各大互联网公司的客户端都开始往动态化方向进行研发,如58的珊瑚海、美团的 容器化方案、字节的lynx(开源版本已停止维护)、阿里的Tangram与LuaView、快手KRN/TK、微博的UI动态化项目。这些项目表明在业界,中大型客户端APP都在往底层高度聚合、上层业务逻辑动态化、脚本化的方向前进。在这些方案中,有一个明显的共同点,即将表示层与业务逻辑层做了明确隔离,通过动态绑定机制完成表示层的事件处理。此外,无论这些APP是否明确提出容器化概念,他们在架构演进的方向上无一不透露着将业务逻辑与非业务逻辑进行彻底隔离的思路:其中业务逻辑部分往多平台、快速开发、快速部署、快速验证的方向走,让业务人员不再关心开发平台的区别,专心业务逻辑实现;而底层框架则往高性能、高可用、跨平台、使用C/C++等通用代码方向走,让底层框架开发团队进行开发维护。这种行业趋势无疑说明我们提出的容器化的大方向是经过业界同行共同验证的,只不过各家的实现路径有所区别而已。
小结
因此接下来我们将详细阐述新的客户端容器化架构,新架构吸收过往的应用架构设计经验,基于我司平台的业务特性,融入了全新的行业发展方向。以容器化为基础,充分利用了平台化相关的工作成果,并深度结合游戏等多引擎共存的思路,从而形成了我们具有业界领先的技术性质与独特的行业属性的新架构。
New Age——新目标
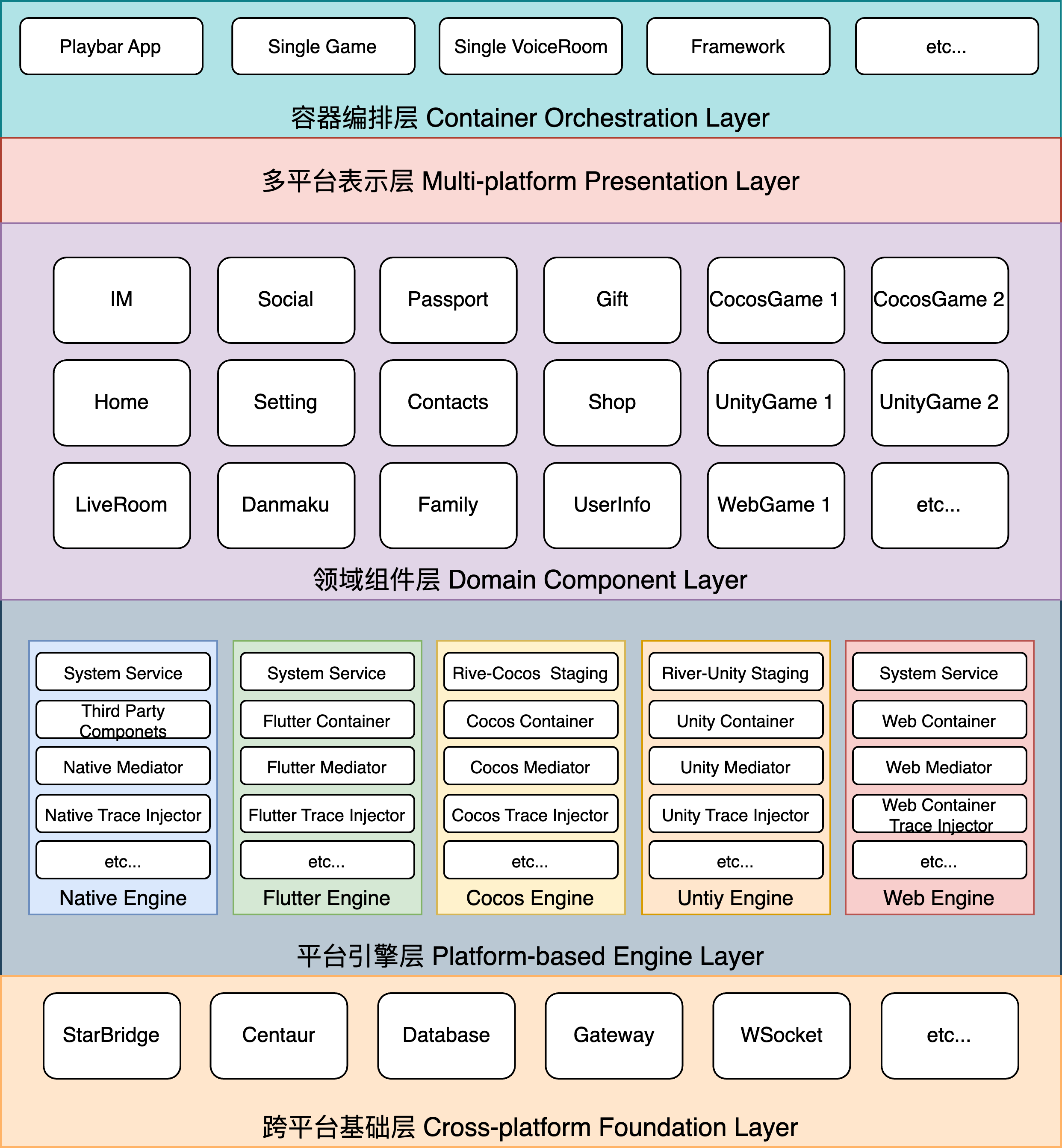
Intro——架构简介{#dl}
新架构从组件代码的视角看分为五个层级:
- 以Rust/C/C++等跨平台代码为基础的
跨平台基础层(Foundation Layer)。 - 将客户端原生代码以引擎视角进行打包,剥离其业务属性,将其与其他游戏等渲染引擎并列,构建出的
平台引擎层(Engine Layer)。 - 基于不同引擎构建的特定领域的业务逻辑组件,这一层相对传统的BLL(Business Logic Layer)来说,其对DAL(Data Access Layer)并没有直接依赖,而是通过消息机制和间接引用的方式,让BLL与DAL实现IoC(依赖反转),同时彻底切断BL组件之间的直接耦合。通过这种做法使领域代码高度聚合,一个独立领域可以成为一个独立组件,因此称为
领域组件层(Domain Layer)。 - 以UI动态化脚本为核心,可以实现跨平台UI代码编写、动态化UI展示的
多平台表示层(Presentation Layer)。 - 将多种引擎组件管理、多种产物输出形式、多渠道发布方式等工作流内容,统一进行编排管理。传统的APP包的概念将在这一层作为一种容器产物进行输出,因此该层称为
容器编排层(Container Orchestration Layer)。
通过上面的简介,我们对新架构的构成已经有了一个大致的了解,接下来我们将自下而上、分章析句、逐步解释每一层在整体架构中的作用和职责。
Cross-platform Foundation Layer——深化跨平台基础能力建设
作为基础支撑组件,高性能是必要条件,并且从底层问题的逻辑同步性的角度来说,使用跨平台底层支撑方案可以提供更强的原理一致性,在去年的跨平台底层技术选型中,我们选择了以Rust为核心,C/C++为辅助的底层组件技术路线。经过一年的探索,Rust在基础层的表现,无论是从性能角度、还是稳定性角度,都足以支撑客户端的上层架构。而在新目标下,首先我们就需要夯实基础,继续深化建设平台底层基础能力,提高对底层代码的可控性、复用性与两端的一致性。
Rust Foundation——扩展基于Rust的跨平台底层组件在项目中覆盖范围
基于上述判断,我们需要扩大Rust基础组件的使用范围,逐步将所有基于原生平台实现的基础组件下沉到Rust层,目前我们已经实现了长链、短链、路由、持久化、数据库等底层能力,Rust Foundation层已经基本建设完成。并且这些组件已经有了一定的线上验证结果,接下来我们应该跟随版本提高底层组件的覆盖范围,加快底层组件的迭代效率与旧业务依赖翻新。
Client Gateway——构建基于DSL的跨引擎通信机制
在1月,我们设计了客户端网关方案,在这个方案中我们定义了一套Client Gateway(客户端网关)的概念:在多个容器引擎之间建立一套消息通信机制,使消息可以在多个编程语言、多个运行环境之间传递,甚至通过Client Gateway上的处理脚本,可以完成复杂的消息转发机制。
我们设计的Client Gateway,包含以下几个重点特性:
- 点对点消息传输,通过
Client Gateway可以实现任意语言之间的消息通讯,从而解决多语言跨平台之间的消息通讯障碍,这一部分的核心是StarBridge组件。 - 消息中转,
Client Gateway可以使用我们的私有协议完成一条消息的多节点跳转,实现消息重定向能力,自动完成复杂消息传递链条。 - 消息协议转换,通过
Client Gateway的消息可以完成不同协议之间的自动转换,例如可以同时接受River、Panda等不同协议的消息,从而让实现Caller无需知道Callee协议,即可直接完成消息传递,并使得不同协议下的相同功能调用,实现方只需要实现一次,避免重复开发,完成实现方的统一开发。 - 权限验证,从
Client Gateway的内部可以清晰识别Caller与Callee之间的关系,因此在这一层对Caller进行权限验证是非常方便的,利用Client Gateway在全局调用关系中的Center位置,可以将校验逻辑完全脱离具体业务,从而实现高度内聚且独立抽象的、可复用的验证组件。 - 消息内容管理,在未来的定位中,所有的跨组件消息将全部通过
Client Gateway进行消息传递,并且其内可以获取所有的消息协议模型,因此可以完成一定程度的内容管理,可以作为消息监控的最佳切入点。
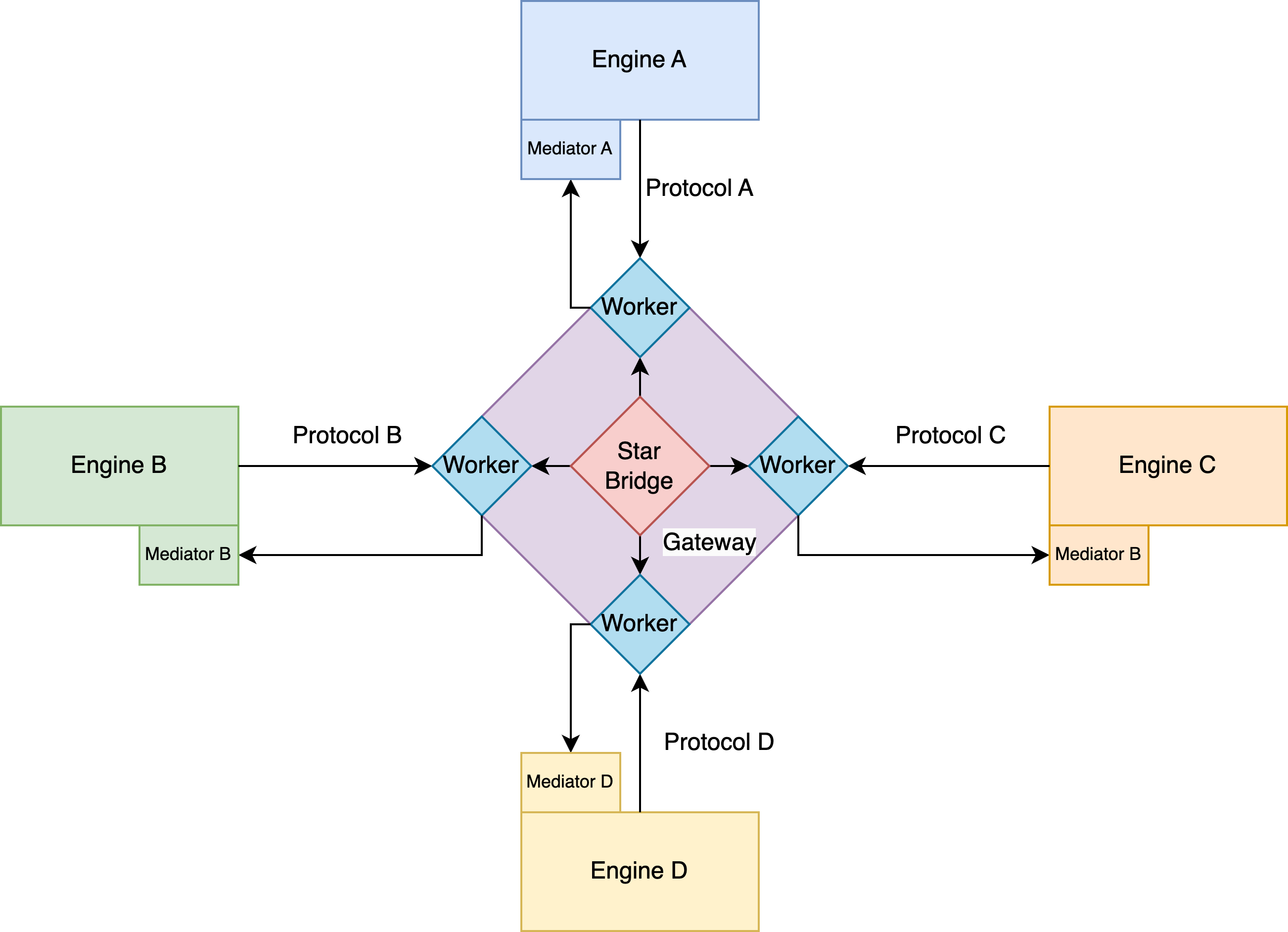
从上图可以看出,Client Gateway是基于StarBridge的框架,但是在StarBridge的基础之上添加了诸多能力。为了防止开发业务时,处理这些复杂的调用处理逻辑导致整体架构被污染,我们将其拆分成了两部分:一部分是纯粹的计算逻辑,将其作为类似纯函数的无副作用代码从整体逻辑中剥离,作为运算子;另一部分可能与业务性质相关的逻辑则通过Client Gateway的DSL解释器完成逻辑处理,这部分使用外部配置文件的方式进行逻辑注入。
因为我们的Client Gateway是基于Rust语言实现的,在Rust平台构建私有DSL解释器有着强大的社区支持(前端领域有非常多的基于Rust实现的DSL解释器),实现难度相比其他平台难度会大幅度下降。并且由于其优秀的跨平台性质,因此基于该框架的Client Gateway DSL Configuration也是跨平台的,其具体方案可以参考客户端网关DSL文档。
在新架构中,Client Gateway作为沟通领域组件的桥梁,将起到极其重要的作用,同时开放平台在客户端上的需求将在这一框架上完全满足。
Data Collector——数据收集与性能监控
在数据收集与性能监控上,客户端已经开发探索了数个版本的基础框架,从早期的wbLogger到后来基于relic的APM项目、从崩溃信息收集到埋点事件,我们的数据收集相关框架已经集成了太多组件,在使用上也显得凌乱无序,各有各的用法,尤其对于持久化、上报信息、后期分析等环节,由于不同日志的格式不同,也无法进行统一处理,每一种数据都得独立实现一套后端工作(这里的后端是指存储、上报、分析等)。同时由于各项数据的记录之间都毫无关联,在后期分析上难度也显得很高。因此我们决定开发一种可以用于所有场景,高效复用各个数据处理环节,并且能够有序归档出任何基于时间轴的数据列表的数据收集框架:DataCollectionSystem(简称DCS)。这一块的详细内容可以参考数据收集组件开发设计文档,本文只对其进行简单介绍,并着重阐述其对于新架构的作用。
DAG Scheduler——因果调度器
DCS的核心是一个DAG Scheduler(Directed Acyclic Graphs Scheduler)。DAG的中文名称叫有向无环图、又称为因果图(如下图所示),这种调度器在Spark中很常见,它的作用是将数据处理流程拆分成多个环节(Stage),利用Stage的原子性和重复性可以实现计算流程的优化,如可以合并相同节点上的计算操作。

从上图中可以看出,在这种具有依赖顺序的环境中,DAG是允许具有重复节点的,因此我们可以将一些数据处理操作设置在重复节点上,以此节省计算资源和数据逻辑操作流程。
在Spark中的DAG里,其Stage拆分是靠识别RDD的依赖关系,区分宽窄依赖,再对宽依赖用Shuffle切分RDD图来完成的,这种做法需要对调度器对RDD图进行不断回溯,每遇到一个Shuffle就断开,遇到一个窄依赖就归并到同一个Stage,不断循环往复,直到DAG生成。这种基于动态回溯的机制在客户端的日志收集系统上过于繁琐,同时客户端的日志处理流程中对于Stage的划分相对明确,数据处理流程与数据类型有限,因此我们选择在这一阶段通过开发手动设置,降低了开发难度。其操作流程大致如下图所示:
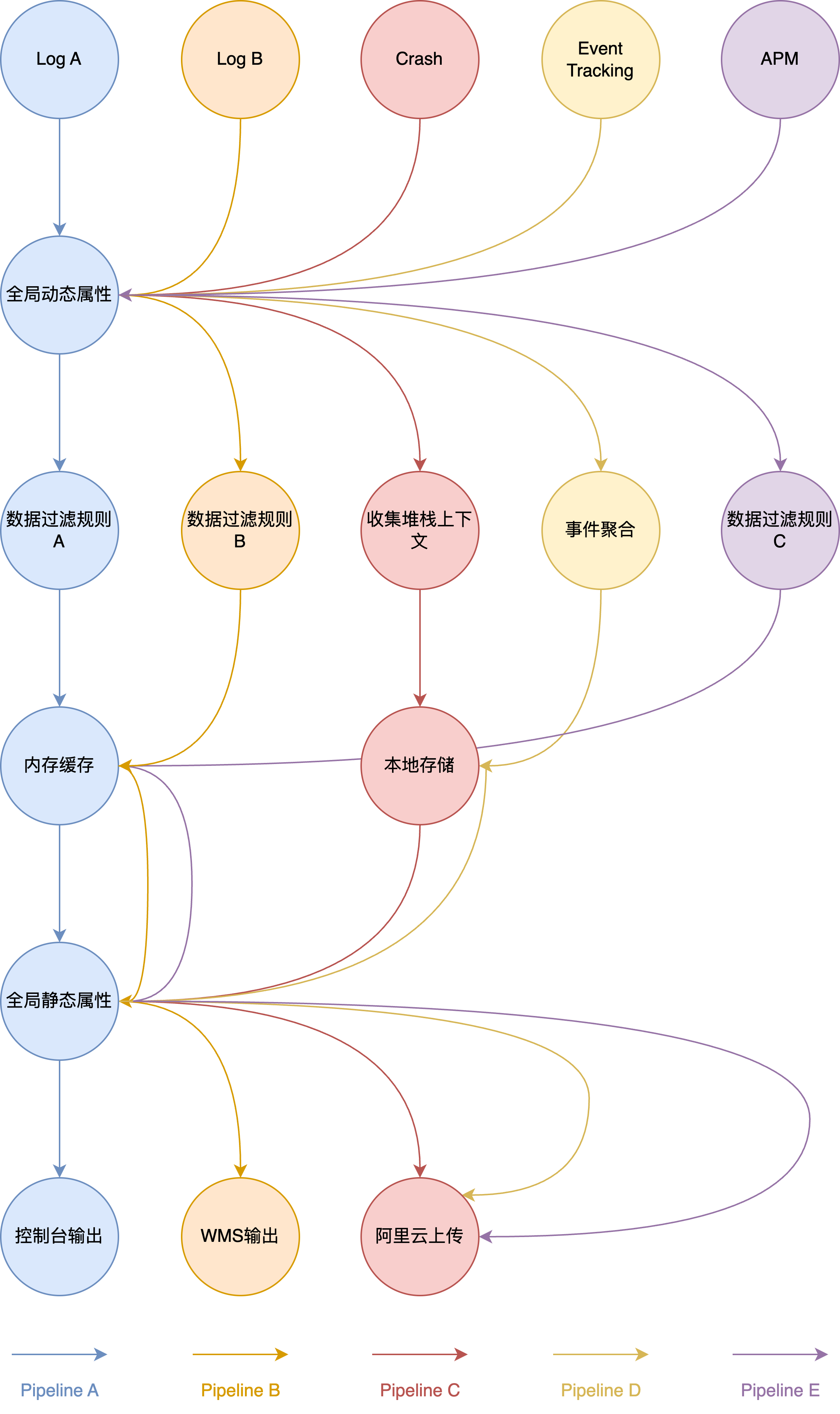
在数据收集相关的实际情况中,我们的数据源有多重来源,如日志、埋点、崩溃信息等,有些任务必须按照特定的顺序执行形成一个队列的任务集合,有的任务则可以直接并行执行;有的Stage是多个流程公用的,有的则是流程独有的。在新的DCS框架下,我们将统一所有的数据收集相关操作,并完成高度抽象化的流程管理和数据处理。
Business Scene——业务场景集成
一个工具再好用也需要在合适的业务场景使用,并为业务场景的开发运营提供助力。依据公司业务方向战略规划与技术部年度技术方向规划,我们将在以下三个方面着重阐述DCS的作用,这三个方面分别是:
- 游戏数据追踪能力
- 平台业务场景数据追踪能力
- 深化性能监控能力在各个领域的反馈作用
Game Data Tracking——游戏数据追踪
由于游戏引擎的特殊性,以及我们基于脚本实现业务逻辑的特性,对于游戏内异常信息的追踪一直没有特别好的办法。我们的游戏开发人员对于崩溃、内存异常、渲染效率低下等问题只能通过本地调试进行排错,难以对线上问题进行快速跟踪,因此我们将以DCS为基础,建立一套游戏数据追踪机制,帮助游戏开发同学快速解决问题。
我们认为,对于游戏出现的问题主要分为两类:第一类是由于引擎自身的问题,导致的运行异常;另一类则是由于业务方的不规范调用导致异常传递到了引擎层。
由于游戏引擎是由第三方公司提供的,我们并没有直接修改的能力,并且开发用户群体庞大,原则上引擎自身不会有严重的无法绕过的异常问题,因此我们可以基本忽略第一种情况,以针对第二种情况的形式进行检测。
同时由于我司平台下的特殊的游戏加载机制:一般的游戏引擎的资源在App的生命周期内并不会彻底清理,但是我司需要用一套引擎在一个应用生命周期内运行多个完全不同的游戏,而游戏引擎一般又无法提供对于旧资源彻底清理的能力,很多全局静态信息无法彻底回收,导致内存泄漏与全局状态混乱。对于这类问题我们只能通过优化引擎资源加载方式等方式逐步优化。但更多的情况,我们还是需要有一套足以满足除游戏加载机制之外的问题的排查手段。
目前我们对于由游戏导致的异常崩溃问题,只能从原生的崩溃堆栈中猜测游戏运行环节,通过对异常捕获的场景信息的添加,目前已经可以知道崩溃时运行的是什么游戏,但是并不能追溯到具体的游戏场景甚至游戏业务代码,只能通过开发经验来猜测。其根本原因在于游戏脚本的虚拟机与原生环境的内存环境进行了隔离,两者之间不能直接访问,其表现形式大致如下:
![]()
而在使用DCS之后,我们可以利用DCS的全平台接入的特性,在游戏脚本虚拟机中直接嵌入DCS的数据追踪注入器。通过实时记录当前游戏正在执行的脚本,与出现异常问题时,游戏手脚架层通过引擎捕获的异常信息进行时间轴关联,合并为一条DCS Pipeline。甚至可以同时添加获取当前设备性能开销等状态,将多方面可能相关的信息绑定在一条时间轴上,从而达到快速定位异常代码的效果:
![]()
通过DCS进行自动合并归因的数据,将提供极高的参考价值,其在游戏的应用范围不仅仅只是异常信息捕获,包括游戏性能优化等场景都可以利用该系统获取具有价值的数据,从而提高游戏运行的稳定性。
Scene Tracking——场景数据收集
与游戏数据追踪类似,对于平台业务,一样可以通过注入DCS Tracking Injector的方式进行数据追踪,利用该机制,我们可以在线上代码添加大量的Debug与Log记录标记,通过基于场景的数据分类机制与自定义标记开关,实现针对特定场景的线上线下数据收集,这样在上线新业务或者重构旧业务时,可以获取大量强关联的有效数据,从而大幅度简化后期数据归因的难度。
APM——扩展性能监控的应用场景
目前我们的App性能数据收集已经相对较为完善了,问题在于难以与实际场景相结合。通过DCS中Stage组合的形式,我们可以将性能监控相关的数据合并到任意平台业务场景/游戏场景中,对各种场景完成性能评估,从而提高性能数据在真实业务场景的实际作用。
参考资料
美团移动端基础日志库——Logan Logan:美团开源移动端基础日志库
Platform-based Engine Layer——构建客户端容器引擎
在新架构上,我们将所有的业务承载平台,称为容器引擎。
Container Engine——容器引擎{#ce}
什么是容器引擎?例如将Cocos引擎与River-Cocos、Cocos原生容器、Cocos Mediator、Cocos Game Data Tracking打包在一起,提供一套业务开发平台,就可以称为Cocos容器引擎。
相较于之前的架构设计,新架构的特殊点在于,我们将Native运行平台也作为一种容器引擎看待,与其他引擎处于平行关系,而不是将游戏、Flutter等引擎建于Native之上对待。这么做的目的,是因为从业务视角来看,无论你写的是Java、OC、Lua、Rust、TS,实际上都是业务代码。这种架构设计的基础,是因为我们有Client Gateway这样的跨平台跨语言的通信机制,因此可以脱离语言所属层级的限制,纯粹从业务层级的角度去构建架构,从而保证上层领域层的领域组件的业务纯粹性。
-
System Service——原生系统服务 根据架构图可知,Native引擎相对于其他引擎的主要区别在于需要提供一套可以运行在双客户端平台的通用原生系统功能接口,给上层领域层提供统一的调用接口。有了原生系统服务可以基本抹平双端的大部分平台差异。
-
Third Party Components Launcher——三方组件启动管理 Native引擎相对于其他引擎的另一个特殊之处在于第三方组件的集成,如TalkingData、数美验证、登陆注册等三方库。同时这些三方库对于启动时机与顺序等是有一定的要求的,因此我们需要提供一套动态注入的三方组件启动管理组件。使用动态列表的方式进行三方库启动设置,可以根据上层业务的集成需求进行反向注入配置,从而让业务与三方库与引擎三者之间互相隔离。
-
Staging——River脚手架 River的实质是基于游戏引擎的外围脚手架,其特殊点在于针对一引擎多游戏的优化处理。由于River是需要基于对应客户端平台组件进行打包构建的,因此对于游戏引擎,River也算作是容器引擎的一部分。
-
Mediator——网关接入点 由于
Client Gateway的内核是由StarBridge实现的,因此需要给每个引擎都实现一套可以调用到容器引擎内部功能的对接入口,即Mediator组件。该组件搭配suit工具包可以通过网关协议描述文件自动生成对应语言平台的功能接口。 -
Container——包装引擎在原生执行的容器 由于整套引擎平台终究是基于客户端平台的代码实现组合而成,而引擎本身是需要一个客户端容器页面来承载的,因此对于非原生页面,其他每个引擎都需要将自己的渲染视图包装到到自身框架内。区别于旧容器框架(如WebView容器、Cocos容器、Unity容器等),新的容器框架将彻底剥离与任何外部协议的耦合,瘦身为单纯运行容器的原生视图组件,其他所有与业务相关的部分全部通过网关协议进行调用,从而彻底剥离业务部分,变为纯粹的容器。
-
Trace Injector——提供信息追踪能力的注入器 由于
DCS需要追踪各个开发平台的场景信息,因此需要在引擎容器层注入一些特定业务场景产生的数据句柄。通过改注入器,可以间接反射控制每个平台的数据收集范围与统一控制开关,从而解决不同场景下数据收集状态难以统一的问题。
容器引擎小结
通过容器引擎层的构建,并通过客户端网关协议进行业务剥离,我们可以获得一个最纯净基础的业务领域运行平台,从而让任意运行环境独立执行并快速随意组合。同时因为与业务无关,因此该方案生成出的容器引擎组件可以任意提供给第三方以二进制包的形式进行集成。这样才能实现业务领域化的组件拆分。
Domain Component Layer——通过领域构建高内聚业务组件
领域组件是什么在简介部分已经进行了阐述,构建领域组件层是我们实现高效业务迭代与完成跨平台容器化架构的必经之路,在下文中我们将从两个方面详细解释领域组件与一般的业务组件之间的区别,以及如何构建一套领域组件。
Business Logic Domain——基于业务逻辑的领域
传统开发中,我们的代码层级与依赖关系大概如下:
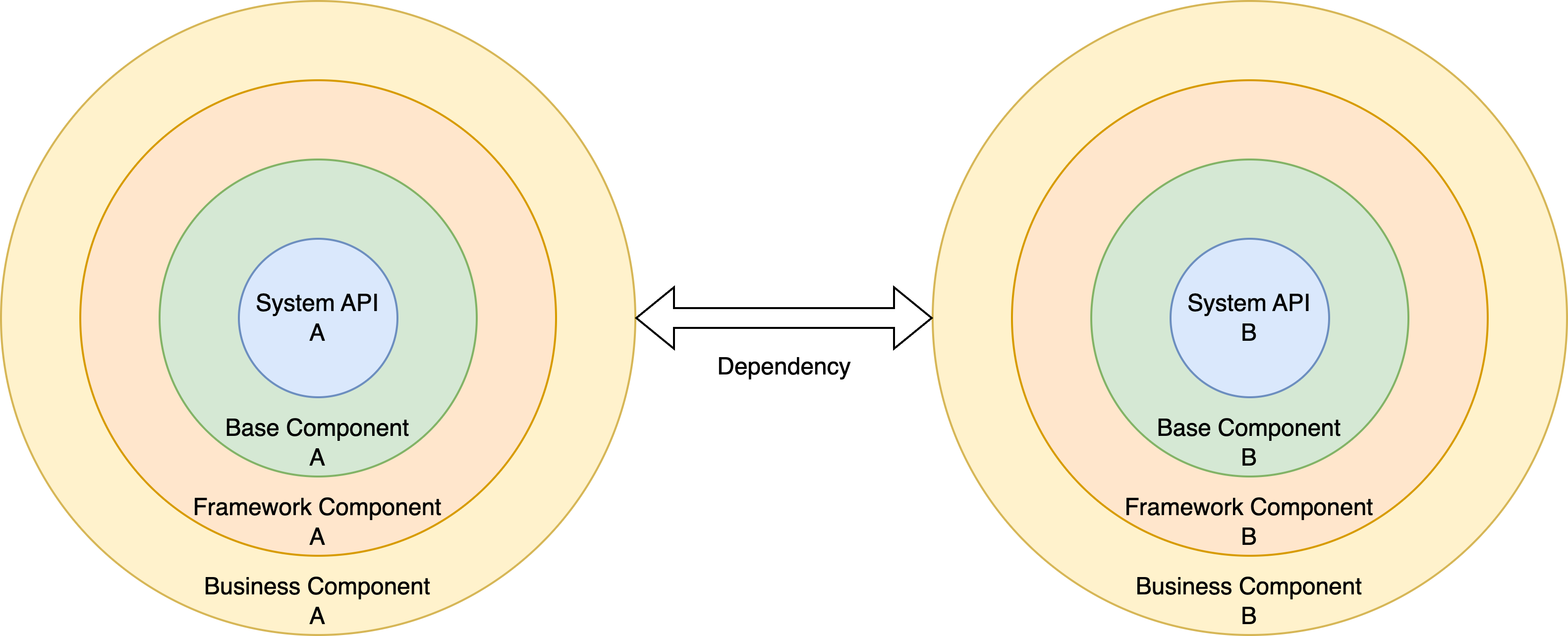
业务代码是基于框架代码包装调用而来,框架代码依赖底层代码,底层代码依赖系统API,逐级依赖;业务代码之间通过直接或间接方式进行关联调用。
从客户端视角来看,由于不存在跨机器的调用关系,因此我们可以将传统领域层概念中的领域服务替换为领域模型,将应用服务替换为业务逻辑。相对于传统模式,其调用依赖关系大致如下:
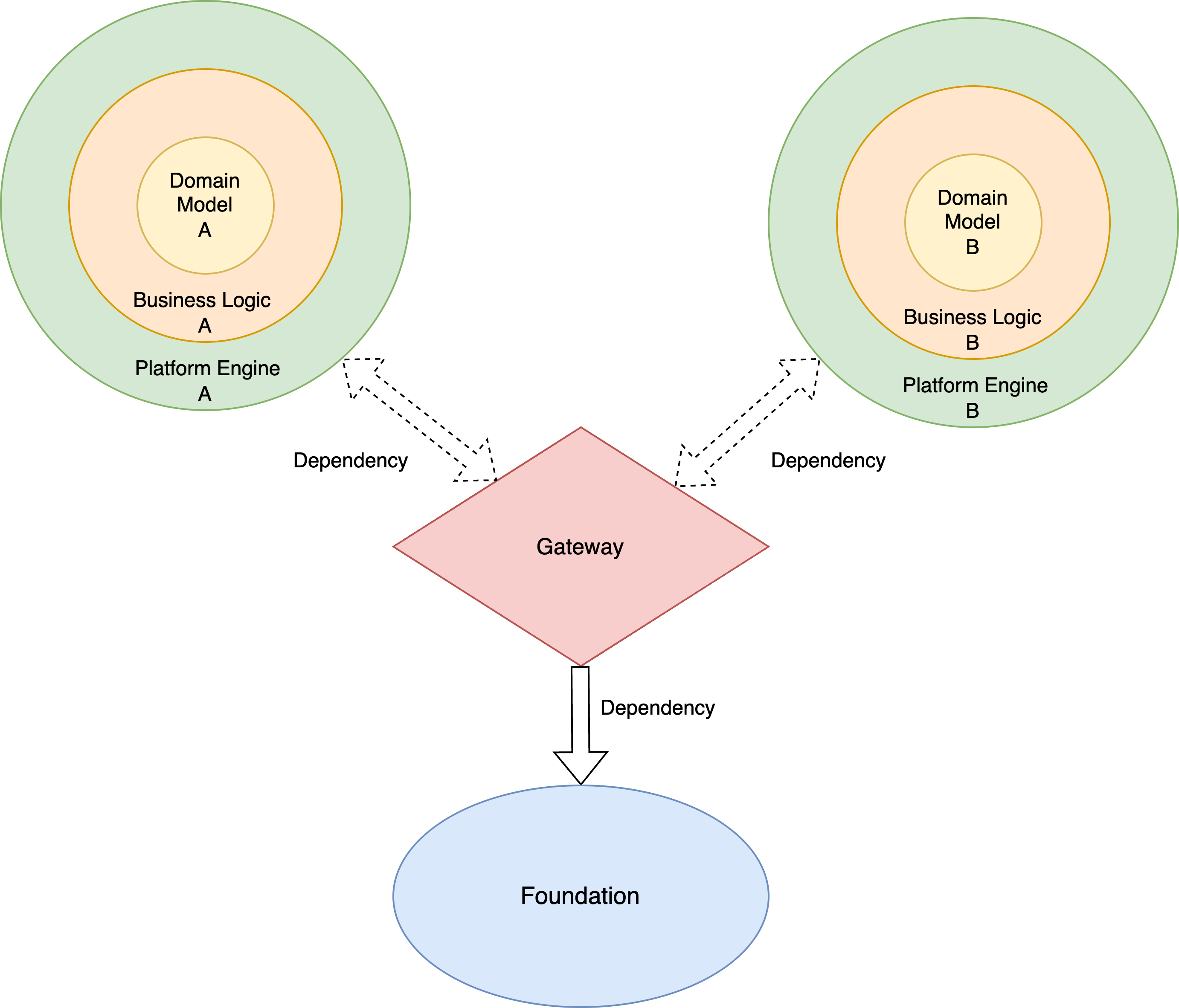
其中业务逻辑之间的耦合通过Client Gateway这类基础API进行隔离,并通过依赖注入的方式让平台引擎反向加载对应平台的业务逻辑。这种形式解除了业务逻辑之间的耦合,通过对业务场景的纵向切割,让不同领域之间通过网关进行通信,实现领域边界的区分。
通过语音房业务架构升级中总结的经验可知:语音房的领域模型其实是其新的ViewModelTree,而业务逻辑则是依附于ViewModelTree组合而成。当我们将语音房中与外部的依赖逻辑全部替换为使用网关进行调用时,语音房就成为了一个独立领域组件,其中的领域模型与业务逻辑本身不再直接依赖任何外部组件。
Business Barrier——业务栅栏,用于隔离UI与业务逻辑
在客户端的业务领域化概念里,我们设想了一套机制,即业务栅栏。业务栅栏的作用是将表示层与业务逻辑层相隔离,从而实现替换UI不修改业务逻辑、修改业务逻辑不影响UI设计布局的效果。这一设计主要是为了配合后续的动态表现层逐步迭代机制而设计。
UIBinder——Automatic Resource Inclusion mechanism
领域相关参考资料
- MVVM 与 Bloc 模式
- MVC、MVP、BloC、Redux四种架构在Flutter上的尝试
- DDD领域驱动-经典四层架构设计及应用详解
- DDD领域驱动设计-经典四层架构划分 + DDD建模分析过程
- JavaWeb-MVC与三层架构
- What is three-tier architecture?
- 3-tier application architecture
- 3 Layered Architecture
Multi-platform Presentation Layer——快速构建UI场景
通过对领域组件层的改造,我们将核心的业务逻辑从UI代码中脱离了出来。对于纯粹的UI表现层的搭建,在绝大部分场景下,性能都不是最关键的问题,而高效更新迭代需求、跨平台的统一搭建机制、可以动态更新的线上UI能力才是最关键的。
目前各大厂商都已经开始大规模使用基于动态脚本渲染界面的UI界面搭建方案,这类方案不但可以大量减少本地代码与资源的体积,同时也增加了业务迭代的效率,从行业趋势而言,往该方向进行探索也是我们的必选项之一。
注:由于苹果审核机制可能有变,本段待更新。
数据绑定相关参考资料
- WPF的数据绑定
- 《WPF》–DataContext数据双向绑定
- MVVM在Flutter中的实现
- 灵魂拷问:flutter构建应用的方式是否是一种倒退?
- App architecture: MVVM in Flutter using Dart Streams
- flutter_state
- Flutter: MVVM Architecture
- Provider in Flutter
Container Orchestration Layer——快速构建业务输出结果
将App做成壳容器已经成为了业界共识,将业务分为独立的领域组件,根据需求集成到不同的壳容器内,从而屏蔽不同类型输出产物的问题,从而提高业务的服用度。
而容器编排正是对App壳容器的动态化配置系统,通过容器描述文件,自动生成多平台的多产物结果,同时提供对于整套业务领域组件的管理配置机制。
Workflow Manager System——工作流管理系统
我们在2年前开发了一套WMS系统,但当时主要是针对iOS平台的组件化组件管理机制构建的,在新的容器化方向下,我们需要对该系统进行迭代,以适应容器化下更多的动态配置的需求。该系统主要包含以下几个部分:
-
FDE(Front-end Develop Environment)——基于我司平台的前端开发环境 由于现在的开发环境已经不止局限于OC/Java等原生语言,为了统一语言多平台开发环境与配置效率,我们需要搭建一套可以在原生语言、底层语言、脚本语言、描述配置文件之间快速开发的整套平台。其中应该包含:仓库管理、组件依赖管理、版本管理、资源管理、开发工具管理、本地调试工具管理、远程配置管理的一篮子系统方案。
-
Product Publisher——应用自动打包发布器 利用gitlab pipeline,根据打包条件自动生成特定产物与输出平台,如可以根据策略选择输出App还是Framework/ARR,或者根据策略自动加固、自动上传至应用宝或者豌豆荚,这样可以最大化利用自动化流水线机制,避免人工操作行为,大幅提高提包效率。
-
Analytical Report——基于自定义条件的多维度分析报告 旧系统中除了WMS Desktop,还有一个WMS Analysis,该组件用于本地性能数据收集与分析。在新系统中我们会将线上数据收集配置、日志拉取、警报配置等功能全部集合进来,从而统一数据收集、异常处理、日志分析、线上报警等功能。
客户端容器化相关参考资料
- https://blog.51cto.com/zhangchiworkos/2714294
- https://www.runoob.com/docker/docker-swarm.html
- https://www.alibabacloud.com/tc/knowledge/what-is-containerization
- https://aws.amazon.com/cn/what-is/containerization/
- https://www.ibm.com/cn-zh/topics/containerization
- https://learn.microsoft.com/zh-cn/dotnet/architecture/microservices/container-docker-introduction/
- https://devpress.csdn.net/cloudnative/62f40334c6770329307f8fbc.html