背景简介
在我司的发展中,业务系统逐渐复杂化,微服务的规模也在不断膨胀,而对于后端乃至整个应用体系的可观测性一直缺少一个系统化的方案。这些问题主要分为四类:
- 故障定位困难,用户一个简单的操作,可能背后会涉及到十几个甚至数十个微服务去共同完成,一旦出现问题,排查起来将十分困难。
- 容量预估困难,在微服务系统中由于每个服务在不同链路中的重要性与参与度并不相同,我们并不能对每个系统做等比例扩容,因此相对精准的容量预估很困难。
- 资源浪费多,这也是由于无法准确预估容量导致的一个结果,同时也隐含了性能优化困难的问题,比如一个业务执行缓慢,由于链路关系复杂,无法直观确定瓶颈,需要进行针对性的排查,导致优化滞后迟缓;同时此类问题不断积累,为了快速解决问题,可能就粗暴的对整条业务进行扩容,逐渐导致资源浪费。
- 链路梳理困难,对于业务新人来说,想要熟悉一个业务系统会非常迷茫,由于没有明确的“地图导航”,很容易让人在其中迷路,开发时不知道自己的系统被谁依赖了,也不知道自己的系统会影响那些下游。
为了解决以上这几个问题,业界一般都会通过与运维团队和数智团队合作,构建分布式可观测链路追踪的形式来解决。本文将对基于我司业务形态与技术栈特性,对后续的基建工作做预研与规划。
什么是可观测性
对于微服务架构来说,由于将整个应用程序拆分成了很多独立开发部署的服务单元,为了保证程序的有效运行和故障排除,对于整个系统的运行情况的观测与追踪成为了基架的关键工作。 一般来说可观测性工具的构建基础是基于可观测性数据来的,业内一般对可观测性数据进行如下维度划分:
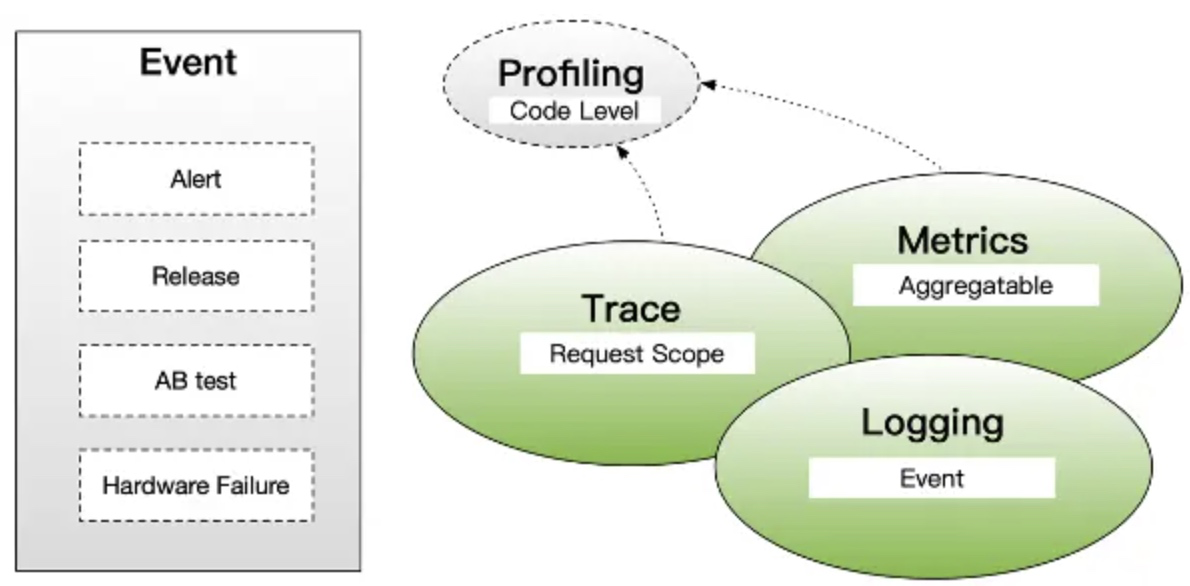
- 度量(Metrics): 度量指标是数值数据,用于表示应用程序的性能和资源利用情况。常见的指标包括请求响应时间、CPU利用率、内存使用情况等。这些指标可以帮助运维团队实时监控应用程序的状态。
- 追踪(Tracing): 由于微服务架构的分布性质,了解请求如何在多个微服务之间传递和处理变得复杂。分布式追踪工具允许您跟踪一个请求或事务的流经多个微服务的路径,并测量每个微服务的性能。
- 日志(Logging): 微服务应用程序会生成各种日志,包括错误日志、访问日志、性能日志等。这些日志用于记录应用程序的运行时信息,以便后续故障排除和分析。
- 性能分析(Performance Profiling): 对微服务进行性能分析,以确定瓶颈和性能优化的机会。
- 报警(Alerting): 基于日志和指标数据,可设置警报规则,以便在应用程序出现问题或性能下降时及时通知运维团队。
- 事件(Event):事件在可观测性中用于记录和追踪重要活动、状态变化和用户操作,以支持监测、故障排除和性能分析。
对于可观测性的整体介绍,可以参阅这篇翻译的文档:可观测性白皮书
设计目标
系统设计目标
对于我司的分布式可观测性系统我们希望能达到以下的效果:
- 全链路追踪:对于请求链路可以完成全链路的追踪,结合业务日志快速定位故障原因
- 可视化数据大盘:记录的阶段性数据足够详细,可以做后续的性能分析
- 依赖分析优化:统计每个调用环节的可用性,对业务依赖关系的优化提供数据支持
- 链路分析优化:通过跟踪分析用户的行为路径,优化整体调用链路,优化业务逻辑
组件设计目标
全链路监控系统组件的一些目标要求:
- 高性能:数据收集组件服务的影响应该做到足够小。服务调用埋点本身会带来性能损耗,这就需要调用跟踪的低损耗,实际中还会通过配置采样率的方式,选择一部分请求去分析请求路径。 在一些高度优化过的服务,即使一点点损耗也会很容易察觉到,而且有可能迫使在线服务的部署团队不得不将跟踪系统关停。
- 低入侵:作为业务组件,应当尽可能少入侵或者无入侵其他业务系统,对于使用方透明,减少开发人员的负担。 对于应用的程序员来说,是不需要知道有跟踪系统这回事的。如果一个跟踪系统想生效,就必须需要依赖应用的开发者主动配合,那么这个跟踪系统也太脆弱了,往往由于跟踪系统在应用中植入代码的bug或疏忽导致应用出问题,这样才是无法满足对跟踪系统“无所不在的部署”这个需求。
- 可扩展:一个优秀的调用跟踪系统必须支持分布式部署,具备良好的可扩展性。能够支持的组件越多当然越好。 或者提供便捷的插件开发API,对于一些没有监控到的组件,应用开发者也可以根据需要自行扩展。
- 好分析:分析的速度要尽可能快 ,分析的维度要尽可能多。 监控跟踪系统越能提供足够快、足够准的信息反馈,开发、运维就越能对生产环境下的异常状况做出快速反应。
业界常用方案对比
| 特性 / 工具 | 实现方式 | 颗粒度 | JVM 监控 | 报警 | 全局调用统计 | Trace ID 查询 | 压测系统支持度 | 管理端功能 | 数据存储方式 | 社区活跃度 | 插件化、定制化难易程度 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| OpenTelemetry | 代码库集成 | 细粒度,支持自定义 | 有集成库(如Micrometer) | 有集成库(Prometheus等) | 可通过度量和导出器收集全局统计信息 | 可以查询特定 Trace ID 的追踪数据 | 可以集成多种压测工具 | 可扩展,支持多种管理端插件 | 多种数据存储后端,包括Jaeger、Zipkin、Elasticsearch等 | 活跃社区,标准化的分布式追踪标准 | 易于自定义,插件丰富 |
| Apache SkyWalking | 代理/Agent、SDK集成 | 细粒度,支持自定义 | 有集成库(如Prometheus) | 有报警集成 | 可通过度量和导出器收集全局统计信息 | 可查询特定 Trace ID 的追踪数据 | 可以集成多种压测工具 | 提供管理端,支持可视化和查询 | 内置存储,支持Elasticsearch和H2 | 活跃社区,有多种插件和扩展 | 支持插件化,较易于定制 |
| Jaeger | 代码库集成、Agent、SDK集成 | 细粒度,支持自定义 | 有集成库(如Prometheus) | 有报警集成 | 可通过度量收集部分全局统计信息 | 可查询特定 Trace ID 的追踪数据 | 需要通过代理/SDK集成压测工具 | 提供管理端,支持基本操作和查询 | 支持多种后端存储,如Cassandra、Elasticsearch | 活跃社区,有众多贡献者 | 提供插件,支持自定义 |
| Zipkin | 代码库集成、Agent、SDK集成 | 细粒度,支持自定义 | 有集成库(如Micrometer) | 有报警集成 | 有一些全局统计信息 | 可查询特定 Trace ID 的追踪数据 | 可以集成多种压测工具 | 有一些管理端功能,支持查询和可视化 | 主要使用后端存储,如Elasticsearch | 活跃社区,有多种语言实现 | 插件支持较少,定制相对复杂 |
| AppDynamics | 代理/Agent | 中等粒度,事务级别 | 有集成的应用性能监测 | 内置的应用性能报警 | 提供全局性能概览和统计信息 | 可查询特定 Trace ID 的追踪数据 | 可以集成多种压测工具 | 提供丰富的管理端功能,监测和分析 | 内置数据存储,云服务或本地部署 | 有社区支持 | 插件化相对较受限,定制相对较复杂 |
| New Relic | 代理/Agent | 中等粒度,事务级别 | 有集成的应用性能监测 | 内置的应用性能报警 | 提供全局性能概览和统计信息 | 可查询特定 Trace ID 的追踪数据 | 可以集成多种压测工具 | 提供全面的管理端功能,监测和分析 | 内置数据存储,云服务 | 有社区支持 | 定制性有限,以云为主 |
| AWS X-Ray | AWS 服务 | 中等粒度,服务级别 | 有集成的云监控 | AWS CloudWatch 集成 | 提供AWS服务级别的全局统计信息 | 可查询特定 Trace ID 的追踪数据 | 可以集成多种压测工具 | 提供AWS管理控制台,监测和分析 | 数据存储在AWS服务中 | AWS社区支持 | 难以定制,与AWS环境紧密集成 |
根据目前我司的现状,我们对于可观测性方案主要将考察目标放在Skywalking与OpenTelemetry之间,具体的对比结果参考该文档:Skywalking与OTel对比 。
系统设计
一个可观测性系统大致由以下几个模块组成:
- 数据采集器(Data Collectors):数据采集器负责从不同源头收集可观测性数据,包括跟踪数据、度量数据和日志数据。这些源头可以是应用程序、操作系统、网络设备、数据库等。数据采集器的任务是捕获和传输这些数据以进行后续分析。
- 分析引擎(Analysis Engine):分析引擎是可观测性系统的核心组件,它执行数据的处理、分析和可视化。这些引擎使用不同的算法和规则来检测性能问题、异常情况、趋势和模式。它们可以生成报告、仪表板和警报,以帮助管理员和开发者了解应用程序的状态。
- 存储系统(Storage System):存储系统用于长期存储可观测性数据,以便后续查询和分析。这些数据可以是跟踪数据、度量数据、日志数据等。存储系统可以使用各种后端存储解决方案,如时间序列数据库、分布式文件系统等。目前存储使用的是阿里云sls,原则上所有支持的数据协议的云厂商都可以进行集成。
- 数据传输系统(Data Transport):数据协议用于将可观测性数据从数据采集器传输到存储系统、分析引擎和可视化工具。这包括数据传输协议、消息队列、数据管道等。
- 自动化运维(Automatic Ops):用于配置和管理可观测性系统的各个组件。它们有助于自动化监测任务和工作流程。
- 可视化工具(Visualization Tools):可视化工具用于呈现可观测性数据的可视化图表和图形。它们帮助用户监测应用程序的性能和状态,发现问题并进行数据探索。常见的可视化工具包括Grafana、Kibana、Prometheus和其他可视化工具。
这些组件协同工作,构建了一个完整的可观测性系统,使管理员和开发者能够监测应用程序的性能、行为和健康,并采取必要的措施以确保系统的可用性和性能。不同的可观测性系统可以具有不同的组件和工具,具体取决于其设计和需求。
在方案选型上,通过SkyWalking与OTel方案之间的横向对比与跟运维团队进行沟通后,大致选择如下技术栈作为整体系统方案:
- 数据采集与协议采用Open Telemetry的开源方案,服务端使用OTel的Java探针工具进行自动收集与少量手动业务日志埋入,客户端基于DCS进行协议兼容
- 分析引擎与存储系统采用云服务方案,目前使用阿里云SLS服务,基于OTel的数据格式进行归档分析,可迁移至其他兼容支持OTel协议的云服务商
- 可视化工具暂时采用阿里云的SLS Trace分析大盘,这一部分在未来根据数据使用方的需求,也可以通过二次开发Grafana等工具来实现自研
- 自动化运维整个系统需要高度自动化、脚本化,利用OTel带来的全链路可观测性数据协议的统一,便于后续的分析与处理
OpenTelemetry简介
模块构成
- OpenTelemetry API:OpenTelemetry 提供了一套 API,用于在应用程序中编写代码来捕获跟踪数据、度量和日志。这些 API 包括 Tracing API、Metrics API 和 Logging API,将其全部综合起来即为OTLP(OpenTelemetry Protocol)
- Trace Context:Trace Context 是用于管理跟踪数据的上下文信息的规范,用于确保跟踪信息在分布式系统中的正确传递和关联。这有助于构建完整的跟踪路径。OpenTelemetry的Trace Context遵循W3C的Trace Context规范,使用标准协议规则进行数据追踪。
- Metric:Metric中包含了对于OpenTelemetry对于度量数据的协议规范,同时OpenTelemetry官方对于大量的基础框架组件开发了自动收集仪器库,可以自动收集这些框架组件中的度量数据。
- Logging Bridge:Logging Bridge是OpenTelemetry的一套日志桥接协议,可以将主流的日志收集工具(如log4j等)收集到的日志数据进行统一转换桥接处理,并发送至OpenTelemetry Receivers。
- Propagators:用于在分布式系统中传播上下文信息的组件,处理跨越多个服务和组件的追踪信息,以确保在整个请求链中保持一致的上下文,例如HTTP Header处理规则、对于grpc的处理规则等。
- Agent:用于实现 OpenTelemetry API的数据收集客户端(广义客户端)实现,用于收集端侧数据并上报给Receivers。OpenTelemetry官方提供了多种语言的 SDK,包括 Java、JavaScript、Python、Go、Rust 等,并且官方实现了绝大部分常用的框架,也提供了自研开发的插件框架。
- Instrumentation Libraries:仪器库,用于自动捕获跟踪、度量和日志数据,简化数据收集流程路径。对于zeus-rpc等自研中间件,可以通过二次开发Instrumentation Library的方式来完成。
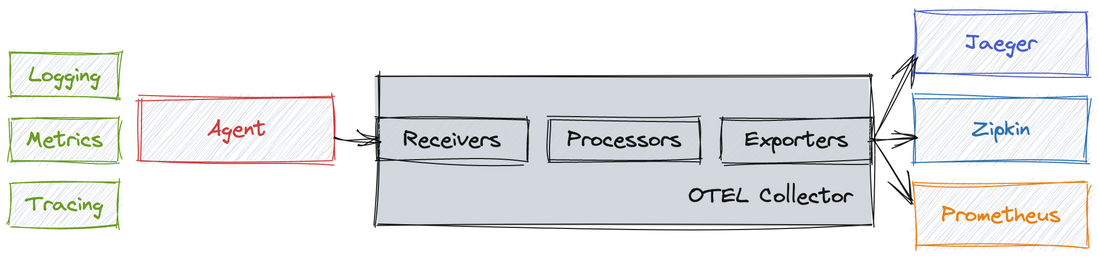
- Collector:该模块是一个可插拔的代理服务,提供标准化的收集处理流程和协议规则,该模块分为三部分,分别是收集(Receivers)、处理(Processors)和导出(Exporters),其结构图如下:
- Receivers:这一块是Collector的第一部分,用于收集各种数据源来的遥测数据,OpenTelemetry的Receivers有很多中协议支持实现,例如Jaeger、Zipkin、OTLP(OpenTelemetry Protocol)、Prometheus、Fluentd、Kafka、SkyWalking等协议都可以支持收集。
- Processors:收集到的数据可能需要进行转换、筛选或增强,以满足特定的需求。Processors提供了处理管道,可以通过配置来执行这些操作,例如批处理(Batch Processor),度量处理(Metric Processor)、追踪上下文处理(Trace Context Processor)、采样策略处理(Sampling Processor)、跨度处理(Span Processor)。
- Exporters:跟踪数据的导出器允许将跟踪数据发送到后端存储或分析系统,如Jaeger、Zipkin、Prometheus 和其他可观测性工具。OpenTelemetry 提供了多种导出器,以便将跟踪数据传送到不同的目标。
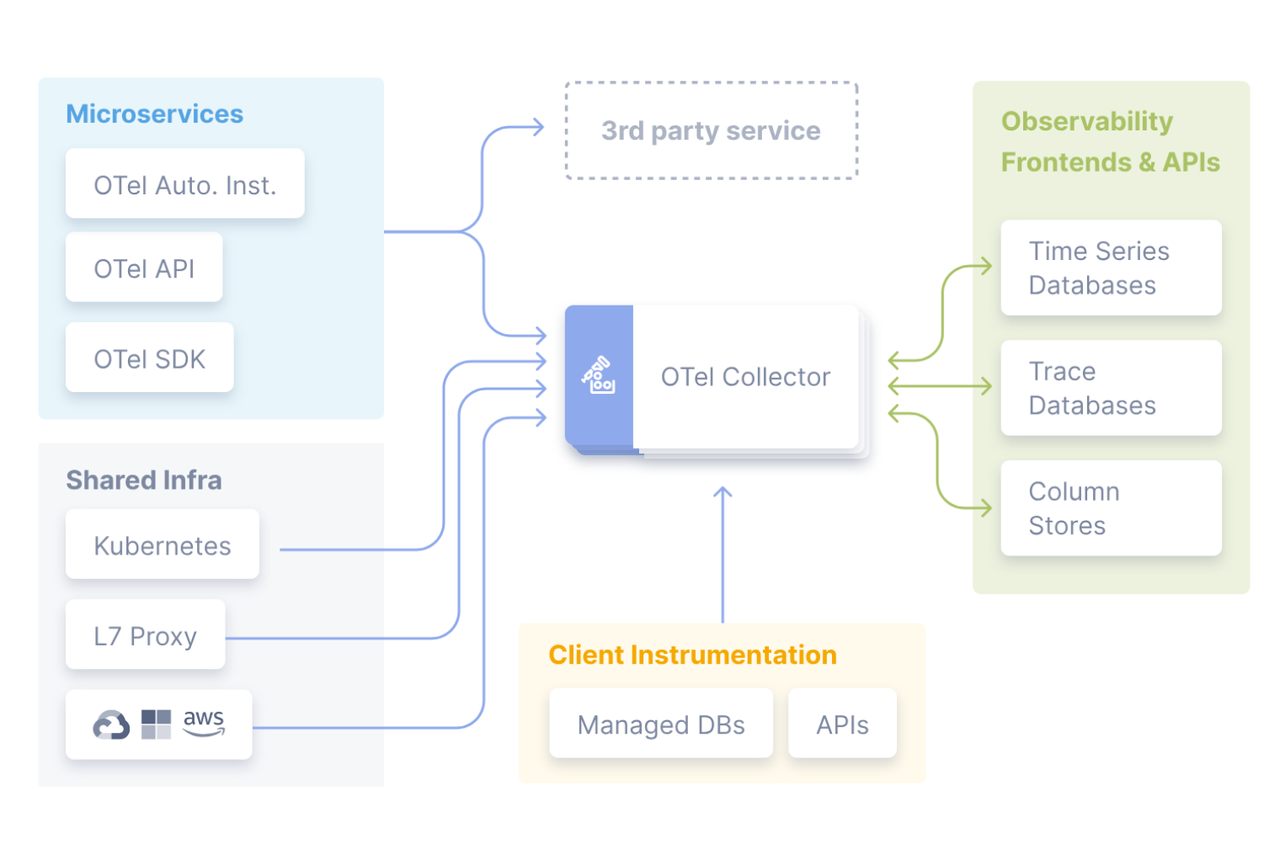
因此在实际场景中,OTel的整体收集架构大致如下:
数据维度
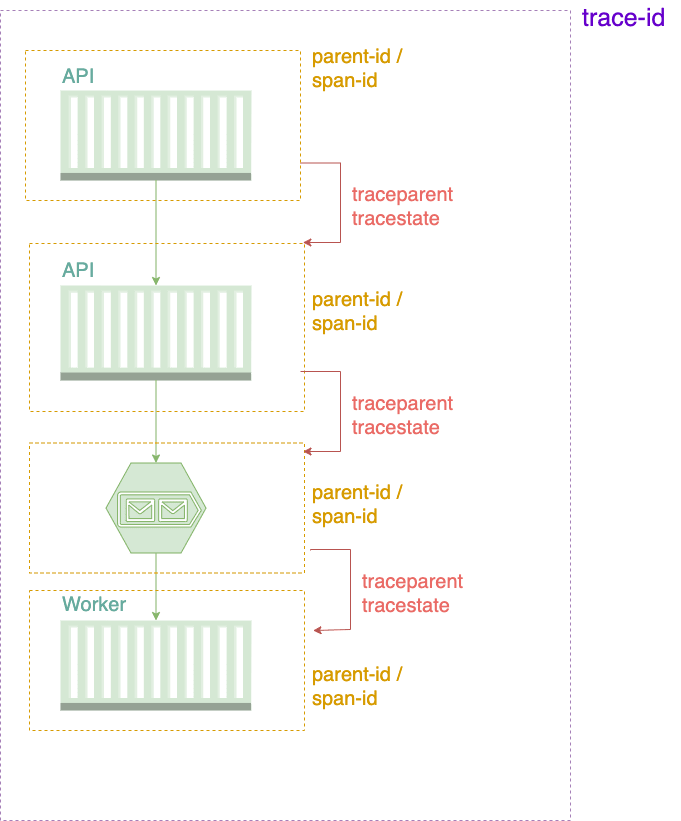
基本数据格式
W3C Trace Context 中的主要依靠2~3个字段完成追踪:
- traceparent字段
traceparent字段是用于标识和传播追踪信息的重要组成部分。它包含了有关请求追踪的关键信息,可以识别不同服务和组件识别请求之间的父子关系,以确保不同服务和组件之间能够协同工作来构建完整的追踪图。traceparent字段的格式采用RFC5234标准,其中包含四个部分(version-trace-id-parent-id/span-id-trace-flags),其格式如下:
traceparent: 00-xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx-yyyyyyyyyyyyyyy-zz
- 第一个部分
version是8-bit数据, 表示使用的context版本,当前版本为 “00”。将来,如果出现新的 Trace Context 版本,将有助于确保向后兼容性和正确的数据解释。 - 第二个部分
trace-id是16-byte array的追踪标识符,它用于标识一个请求的整个生命周期,确保每个请求都有唯一的 Trace ID。 - 第三个部分
parentid/spanid是8-byte array的跨度标识符,用于标识一个请求的各个阶段,也被称为 “span”。 - 最后部分
trace-flags是8-bit的追踪标志,它们用于控制是否要记录和传播追踪信息的标志。不同的标志值可以表示不同的追踪行为,例如是否记录追踪数据或是否采样请求。 -
所有的字段都使用16进制进行编码 traceparent 字段的主要作用是建立和传播追踪关系。通过 Trace ID 和 Span ID,它允许不同服务和组件识别请求之间的父子关系,从而构建追踪图,追踪请求的流程。 Traceparent 字段用于标识和传播请求的追踪信息,以在分布式系统中建立追踪关系,帮助开发者追踪请求的流程并优化性能。
- tracestate字段
tracestate字段是用于在跟踪上下文中传递与跟踪相关的供应商或应用程序特定数据的字段,例如gw=openresty等。tracestate字段的构成方式是一个逗号分隔的键值对列表。每个键值对由等号(“=”)分隔键和值,并且可以包含多个键值对,以便传递多个供应商的特定信息。 每个键值对应于不同的供应商或应用程序,其格式如下:
tracestate: key1=value1,key2=value2,key3=value3
- baggage可选字段
baggage字段用于传递与跟踪相关的自定义键值对数据,以便在跟踪上下文中包含应用程序特定的信息,如用户uid、应用状态、特定业务数据等。baggage字段的构成方式与tracestate字段类似,也是一个逗号分隔的键值对列表,每个键值对由等号(“=”)分隔键和值。其格式如下:
baggage: key1=value1,key2=value2,key3=value3
HTTP协议
在HTTP协议中,通常将追踪字段埋入HTTP Header中,其格式大致如下:
traceparent: 00-0af7651916cd43dd8448eb211c80319c-b7ad6b7169203331-01
tracestate: rojo=00f067aa0ba902b7,congo=t61rcWkgMzE
baggage: k1=v1,k2=v2
MQTT协议
由于在 MQTT 版本 5.0 之前,无法为消息添加扩展元数据。后续决定升级MQTT协议至V5,通过User Property字段完成Trace信息埋入
MQTT V5大概消息格式:
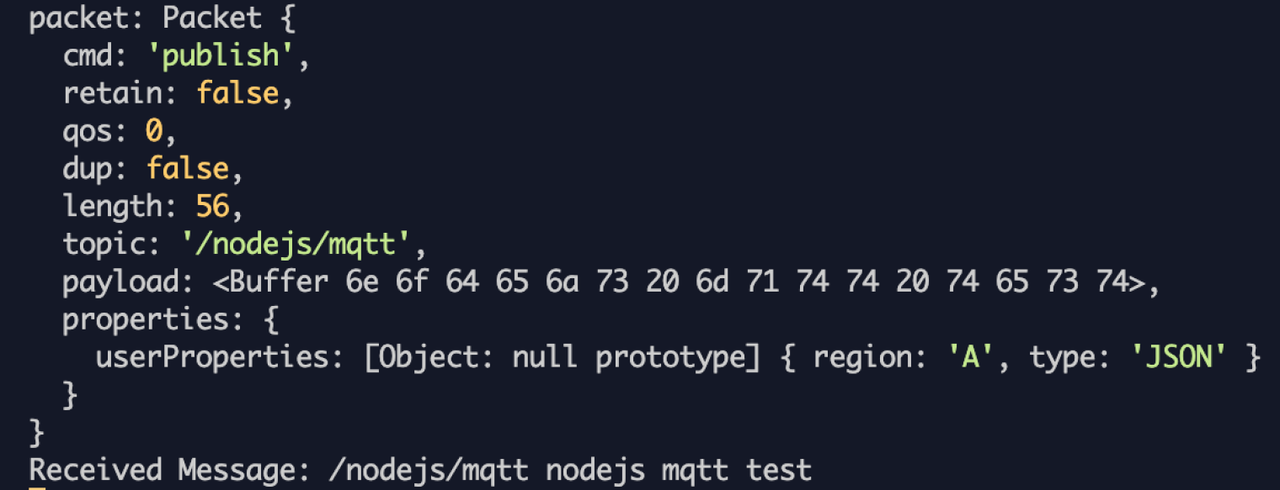 通过在userProperties中埋入traceparent与tracestate字段的方式实现propagation,相关信息参考Trace Context: MQTT protocol。
通过在userProperties中埋入traceparent与tracestate字段的方式实现propagation,相关信息参考Trace Context: MQTT protocol。
数据标准化
在现有的我司TraceId规则上,我们使用如下标准进行的Id生成:
@JvmStatic
fun genTraceId(): String {
val userId = UserInfoManager.getInstance().userId
val timeStamp = System.currentTimeMillis().toString()
val deviceId = AppRuntimeManager.getInstance().deviceId
val randomNum = random.nextInt(10000)
return EncryptUtils.md5("$userId$timeStamp$deviceId$randomNum")
}
可以看到这种生成规则的输出结果由于是md5,因此本身并没有实际语义,只能作为一个区分id,稍微复杂一点的跟踪信息就需要通过查询其他系统的数据并进行关联才能完成数据聚合与链路追踪。 因此对于数据协议应当设计一个更加通用的标准以完成协议标准化,基于OTel提供的标准格式,可以使用类似下面的数据结构:
- Metrics:使用OTel的度量功能和代理来捕获应用程序性能和资源利用情况的度量数据,其数据结构大致如下:
syntax = "proto3";
message Metrics {
repeated InstrumentationLibraryMetrics library_metrics = 1;
}
message InstrumentationLibraryMetrics {
string name = 1;
string version = 2;
repeated Metric metrics = 3;
}
message Metric {
string name = 1;
string description = 2;
MetricType type = 3;
repeated KeyValue labels = 4;
repeated DataPoint data_points = 5;
}
message KeyValue {
string key = 1;
string value = 2;
}
enum MetricType {
GAUGE = 0;
COUNTER = 1;
SUMMARY = 2;
HISTOGRAM = 3;
}
message DataPoint {
double value = 1;
int64 timestamp = 2;
}
在这个示例中:
Metrics表示 OTel 度量数据的顶级消息。它包括一个或多个InstrumentationLibraryMetrics,每个代表一个度量库(Instrumentation Library)的度量数据。InstrumentationLibraryMetrics表示一个度量库的度量数据,包括库的名称、版本以及一组度量 Metric。Metric表示一个具体的度量,包括度量的名称、描述、类型(Gauge、Counter、Summary、Histogram)、标签(labels)和数据点DataPoint。KeyValue表示键值对信息,用于标识度量的标签。MetricType枚举定义了不同类型的度量,包括 Gauge、Counter、Summary 和 Histogram。-
DataPoint表示度量的数据点,包括一个值和时间戳。 - Tracing:集成分布式追踪系统,以监测请求的流经多个服务的路径,其数据结构大致如下:
syntax = "proto3";
message Trace {
string trace_id = 1;
repeated Span spans = 2;
}
message Span {
string span_id = 1;
string trace_id = 2;
string parent_span_id = 3;
string name = 4;
int64 start_time = 5;
int64 end_time = 6;
repeated KeyValue attributes = 7;
repeated Event events = 8;
}
message KeyValue {
string key = 1;
string value = 2;
}
message Event {
string name = 1;
int64 timestamp = 2;
repeated KeyValue attributes = 3;
}
在这个示例中:
Trace表示一个完整的跟踪路径,包括一个唯一的 trace_id 和多个 spans,这些 spans 表示一组相关的活动。Span表示跟踪中的一个活动,包括一个唯一的 span_id、trace_id 以及可选的 parent_span_id 来建立父子关系。它还包括 name(活动名称)、start_time 和 end_time 用于表示活动的生命周期。attributes 存储有关活动的额外信息,而 events 存储与活动相关的事件。KeyValue用于表示键值对信息,用于描述活动和事件的属性。-
Event表示一个活动中的事件,包括事件的名称 name、时间戳 timestamp 和与事件相关的属性 attributes。 - Logging:将应用程序和服务的日志集中管理,以帮助排查问题,其数据结构大致如下:
syntax = "proto3";
message LogEntry {
string trace_id = 1;
string span_id = 2;
string trace_state = 3;
string severity = 4;
int64 timestamp = 5;
string name = 6;
string body = 7;
repeated KeyValue attributes = 8;
}
message KeyValue {
string key = 1;
string value = 2;
}
在这个示例中:
LogEntry代表一个日志条目,它包括了以下字段:trace_id和span_id:用于关联日志条目与跟踪数据。trace_state:用于表示跟踪状态信息。severity:日志的严重性级别,如 INFO、ERROR、WARNING 等。timestamp:日志记录的时间戳。name:日志的名称或标题。body:日志消息的正文。attributes:与日志条目相关的键值对属性。
KeyValue是一个通用的键值对结构,用于表示与日志条目或属性相关的键值对信息。
数据收集方案
服务端大致路径
通过Java Agent等技术,使用字节码插桩的方式在微服务出入口进行自动埋点。对于业务需求的点位,可以通过自定义的方式进行记录。
- 对于RPC消息,需要通过OTel-Instrumentation进行二次开发,实现二进制数据自动处理。
- 对于MQ消息,OTel官方提供了插件可以通过Agent的方式自动收集。
- 对于HTTP请求,OTel官方提供了插件可以通过Agent的方式自动收集,对于API网关也可以通过APISIX-OTel插件进行自动收集。
- 对于MQTT请求,OTel提供了lua sdk,可以通过在OpenResty网关集成OTel-lua组件,然后处理MQTT二进制payload的方式来解决,可以做到对业务完全透明。
- 对于Skynet消息,OTel提供了lua sdk,与OpenResty情况类似,通过二进制或json协议处理做到透明收集。
- 对于Logging数据,通过对接现有log包装框架,可以将log的输出对接到OTel-Logging-Bridge上,有需要的话可以直接转换日志信息并归并到Agent上,并完成追踪信息的自动添加。
客户端大致路径
客户端在今年构建了DCS数据收集方案,基于Rust的核心库可以添加对OTel数据格式的支持能力,从而实现双端数据结构一致。
- 客户端目前基础库基本都由Rust实现,因此进行常规数据收集可以在Rust的网络、数据库等位置进行统一预埋
- 对于业务上的点位,可以通过自定义Logging的方式和场景信息与追踪id绑定的方式进行收集。
数据存储方案&数据检索
如果自建存储,官方推荐如下方案:
- Metrics:将度量数据存储在时间序列数据库(如Prometheus、InfluxDB)中。
- Tracing:使用分布式追踪系统存储追踪数据(如Jaeger、Zipkin)。
- Logging:将日志数据存储在集中式日志管理系统(如ELK Stack、Splunk)中。 考虑目前可观测性方案处于初步启动阶段,目前Trace数据还是选择SLS进行综合存储。使用SLS相对于旧ES存储方案,其单位成本也有相对明显的优势,具体信息可以咨询运维获得实时报价。
数据可视化方案
如果自建可视化大盘,官方推荐使用仪表板工具(如Grafana、Kibana、Prometheus的内置界面)可视化度量、追踪和日志数据。 由于目前考虑采用SLS进行数据存储,可视化这块SLS已经包含了,暂不需要自建处理,未来如果迁移云服务厂商,可以考虑自建大盘或者对接到现有的Grafana大盘上。
其他后续方案
后续还有一些细节处理或善后方案需要更详细的讨论,如:自动报警方案、事件处理方案、自监控方案、自动化修复方案等。 自动报警方案:需配置警报规则,以便根据度量和日志数据的异常情况发送通知。集成警报管理系统,确保团队可以及时响应问题。 事件处理方案:将事件数据(如应用程序生成的事件或警报事件)与度量、追踪和日志数据整合,以帮助理解系统的整体行为和性能。 自监控方案:监控观测系统自身的性能,以确保它不会成为瓶颈或单点故障。 自动化修复方案:利用警报和事件来驱动自动化响应和自愈机制,以减少故障恢复时间。
参考文档
- Observability Whitepaper
- SLS:基于OTel的移动端全链路Trace建设思考和实践
- Trace Context
- Trace Context: MQTT protocol
- Using W3C Trace Context standard in distributed tracing
- OTel中文文档
- 深入可观测底层:OpenTelemetry 链路传递核心原理
- 一文看懂分布式链路监控系统
- 在分布式追踪系统中使用 W3C Trace Context
- aliyun trace demo
- 分布式链路追踪在字节跳动的实践
- 大规模分布式链路分析计算在字节跳动的实践
- SkyWalking插件开发指南
- OpenTelemetry で始めるObservability-AWS
- 可观察性统一方案-SLS兼容OpenTelemetry
- 释放Trace的价值-SLS OpenTelemetry新功能直击痛点